

PHP Filter链——基于oracle的文件读取攻击
简介
一开始见这题今年红明谷的ezphp,利用文件包含来进行测信道攻击获得flag.php的源码,接着利用匿名类来执行命令.不过最初的原题是DownUnder CTF 2022
1 | file($_POST[0]); |
file读取一个文件,但不输出其内容.最终解法就是通过测信道攻击,用报错来预测根目录的flag的文件内容.
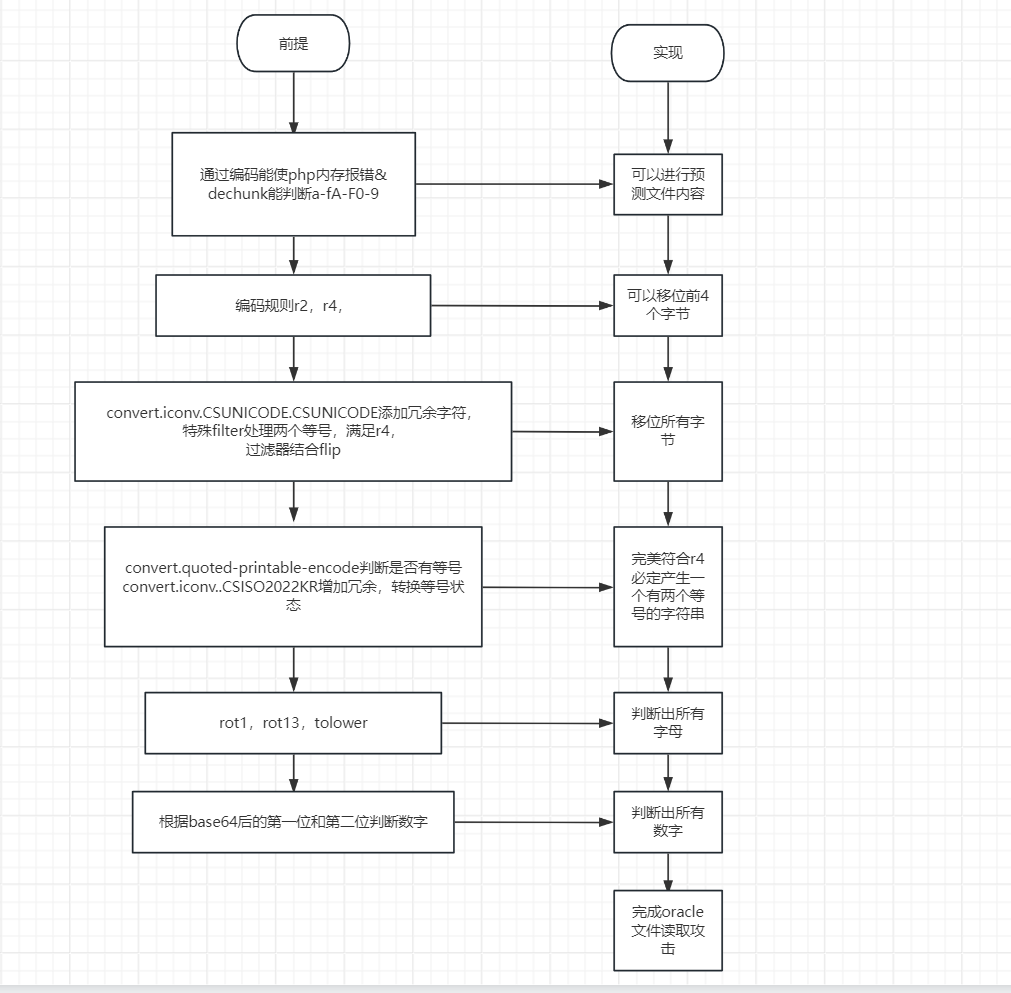
一.攻击原理
大致分为3步:
- 通过iconv函数编码导致php产生内存报错
- 利用dechunk来确定文件第一个字符
- 利用能改变字节顺序的编码,利用iconv将剩余字符与第一个字符交换
1.通过编码来使PHP产生内存错误
众所周知,PHP Filter 当中有一种 convert.iconv 的 Filter ,可以把数据从字符集A转换成字符集B
例:php://filter/convert.iconv.<source-encoding>.<target-encoding>/resource=<filename>
核心:convert.iconv.L1.UCS-4LE 编码
UCS-4编码使用固定4个字节来表示每个字符,其中UCS-4LE即:使最低有效字节存储在最前面
1 | php -r '$string = "START"; echo strlen(iconv("UTF8", "UCS-4LE", $string))."\n";' |

在php中,php.ini的memory_limit参数代表了资源限制,默认值为128MB,如果试图读取大于128MB的文件时就会触发内存错误.
1 |
|
例如这串代码,将字符串START使用了13次UCS-4LE编码,产生内存错误
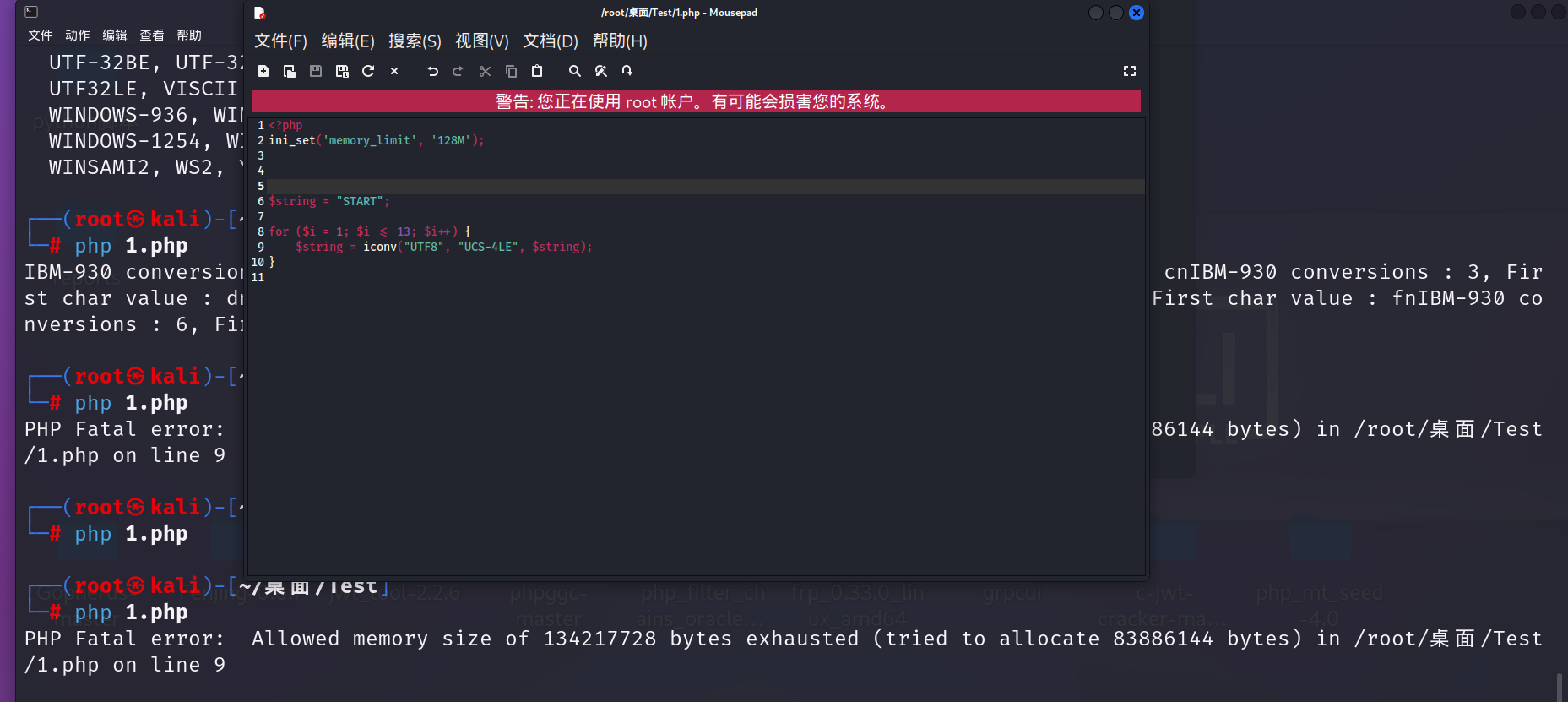
2.使文件泄露第一个字符
在php文档中可以找到php filter dechunk这里,其中对字符处理时有限制,只能处理a-fA-F0-9这个区间中,这是因为对于http中的chunk编码是以16进制来表长度的,所以16进制字符范围在a-fA-F0-9这个范围内.
根据源码可知,php支队第一个字节进行判断,第二个字节无关紧要.
1 | php > var_dump(file_get_contents("php://filter/dechunk/resource=data:,a")); |
可以发现,在使用dechunk filter时,如果我们要编码的字符第一个字节不在16进制编码范围内,php回原样输出,在范围内的话会输出为空.
因为dechunk存在着判断的机制,所以我们可以利用这个机制来作为我们的oracle攻击,此外,我们开可以配合前面的convert.iconv.L1.UCS-4LE 编码,经过多段convert.iconv.L1.UCS-4LE 编码后,如果我们想要泄漏的字符串内容开头的字符范围在16进制编码范围内,因为有dechunk编码会清空字符串,就不会产生内存报错,如果不在就会继续原样输出最后导致报错.
1 | 当前flag文件首字母为a |
所以我们目前可以判断文件中的第一个字符是否在16进制编码这个范围内了,不过现在只能判断第一个字节,接下来就是处理剩余的字节了.
3.泄露剩余字节
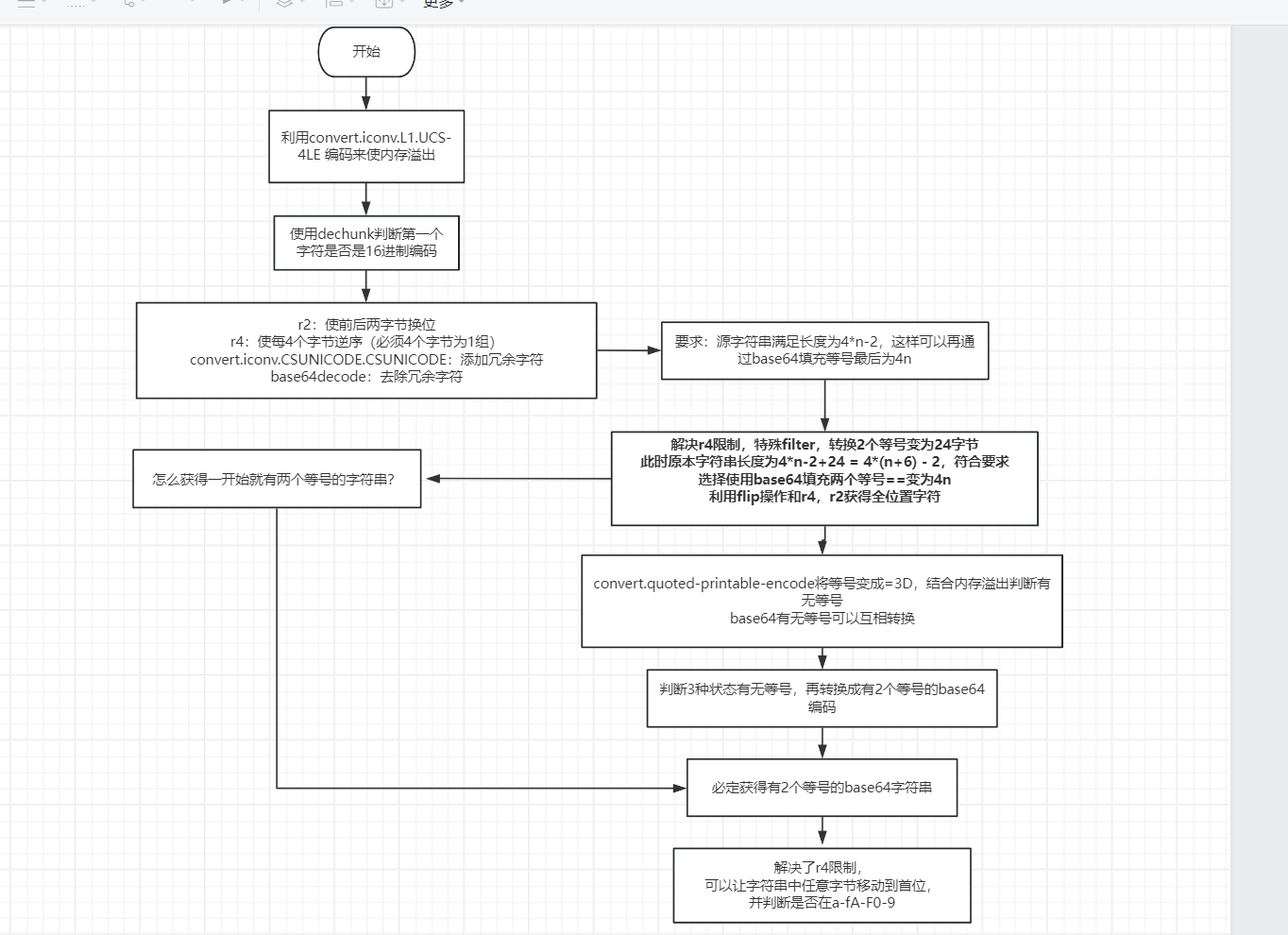
a.处理前4个字节
目前我们可以判断第一个字节了,由于我们使用的时php://filter,那么有没有一种编码可以交换字符串中的字符位置呢?
以此为目的我们可以寻找到:
convert.iconv.CSUNICODE.UCS-2BE这个编码规则,将unicode转成ucs-2BE,利用这个编码规则我们可以前后交换每两个字节的位置,将他称为r2
例如:
1 | var_dump(file_get_contents("php://filter/convert.iconv.CSUNICODE.UCS-2BE/resource=data:,abcdefgh")); |
使用 convert.iconv.UCS-4LE.10646-1:1993 我们可以将每四个字节的位置逆序,我们称这个编码规则为 r4
1 | var_dump(file_get_contents("php://filter/convert.iconv.UCS-4LE.10646-1:1993/resource=data:,abcdefgh")); |
所以我们现在可以找到源字符串中的第一个,第二个和第四个字节,那么第三个以及其他字节呢?
对于第三个字节,我们可以先将他r2,再进行一次r4即可把c放在第一位:
1 | var_dump(file_get_contents("php://filter/convert.iconv.CSUNICODE.UCS-2BE|convert.iconv.UCS-4LE.10646-1:1993/resource=data:,abcdefgh")); |
这样前4个字节我们都可以判断了,但是之后的呢?似乎不能通过r2和r4规则来放到前半部分,
这时我们可以想到之前的filterchain知识,利用filter协议通过各种编码规则组合来对空文件进行写入一句话木马.当时利用的是PHP再处理BASE64字符串时会完全忽略非法字符,我们可以通过一些编码规则来将非法字符添加到字符串最前端,再利用r2/r4组合交换顺序,再利用base64decode清除非法字符即可完成把后续字符交换到前面的操作了.
例如convert.iconv.CSUNICODE.CSUNICODE 编码规则,它可以将字符串最前端加上0xff0xfe
1 | var_dump(file_get_contents("php://filter/convert.iconv.CSUNICODE.CSUNICODE/resource=data:,abcdef")); |
不过这里还有一个问题,这里测试的时候用的是6个字节,因为r4编码规则对字节有要求,一定要4个字节为一组,所以我们需要想一些其他办法.
b.对于base64两个等号的处理
回顾一下上述过程,r4编码规则有两处利用点:
一个是产生填充字符后进行交换,标记为(1).
一个是利用base64消除填充字符后,标记为(2).
对于(1),对于要移位的字符串,我们尽可能让他长度满足4*n-2即可,但是我们根本不知道字符串原本长度是多少.
不过好在base64编码长度都是4*n个字节,但是我们还是需要另外两个字节,因为再base64编码中,分组编码完成后,不足分组编码的会使用=进行填充,所以我们可以利用这两个等号来进行一定的变换操作,使得其他字节不变的情况下满足4*n-2的长度条件.
题目作者找到了这个filter:
1 | var_dump(file_get_contents("php://filter/convert.quoted-printable-encode|convert.quoted-printable-encode|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7/resource=data:,==")); |
**这个filter会固定将两个等号转换成另一个长度为24的字符串,*所以原本的字符串长度就变为 *4n-2+24 = 4*(n+6) - 2* 也是符合了我们上述的长度要求!
所以我们现在以abcdefghij==来测试一下
1 | // 将等号进行转换 |
经过这4步操作后,再利用一下r4即可将e放在第一个字节上.
这4步流程在作者的原本脚本上本定义为一个flip操作,也就是一个flip流程包括:等号转换,添加冗余,r4转换,去除冗余四个步骤.
c.移动所有位置
到目前为止,我们基本解决了8字节中的1-6位置的获取,至于7-8位,我们可以先进行一次r4,然后再次重复上述流程即可获得.
但是超过8字节的位置呢?
观察之前的上述操作,我们引入了冗余字节,最后又剔除了冗余字节,实际上我们每次进行flip操作后,后续的字节都会向前移动,所以我们进行的flip次数越多,我们就能拿到距离开头越远的字符.
例如:
1 | abcd efgh ijkl mn== ->flip-> |
这样我们就可以获得第9位的字符,我们可以观察到规律,以ij为例,每次使用flip/r4都会使这两个字符前进4个字节位置.
所以我们可以根据这个规律,对于下标为 n 的字符,只需要进行 n//4 次 flip/r4 组合就能将其位移到字符串的前端,最后前后可以使用 r4/r2 进行微调就行
作者的脚本中这个算法为:
1 | def get_nth(n): |
d.基于base64来预测
但以上的所有的理论都来自于一个条件,那就是一个拥有两个等号的base64字符串,如果我们将文件内容进行base64编码后并没有两个等号的话,以上就不成立了.
所以我们的目标又回到了如何不依赖文件内容、同时也不能过度修改文件内容的情况下产生一个满足要求的 Base64 字符串。
又或者说,我们有没有办法检测源文件内容经过base64编码后是否有两个等号?
到目前为止,我们又有能够判断服务器的某些条件的oracle只有dechunk,我们是不是可以利用这个 Oracle 来服务其他的判断条件呢?比如此处的等号.
那么有没有一种编码格式可以对数字字母都无效,但是可以把等号变成其他更长字节长度的字符,使得长度过长从而导致服务器产生内存错误呢?
于是我们大概的想法是,如果该base64编码存在等号,经过某个编码使长度无限扩大最终导致服务器内存错误;如果没有等号,那么经过编码就不会导致服务器内存错误
- 根据目的来寻找编码:convert.quoted-printable-encode :
这个编码会将一个=编码成=3D,从一个字节变成了3个字节,而对其他数字字母并不会生效,这完美符合了我们的需求.
所以我们现在的做法就是:
- 获取 Part 1 中 n 组 convert.iconv.L1.UCS-4LE 组合会致使服务器产生内存错误的临界值 n
- 使用 convert.base64-encode|convert.base64-encode 两次 Base64 编码对文件内容进行编码
- 使用大量的 convert.quoted-printable-encode 编码对上一步 Base64 结果中的等号进行数次编码
- 最后拼接上 n-1 组 convert.iconv.L1.UCS-4LE 组合
按照如上步骤,如果我们通过文件内容得到的 Base64 编码中含有两个等号,则会因为后续通过大量的 convert.quoted-printable-encode 编码扩展,拼接上原本不会让服务器产生内存错误的 n-1 组 convert.iconv.L1.UCS-4LE ,致使服务器产生了内存错误;如果没有等号,即使经过 大量的 convert.quoted-printable-encode 编码扩展也不会扩展字节,拼接上 n-1 组 convert.iconv.L1.UCS-4LE 也不会产生内存错误。完美~~!
不过仍有问题,此时我们拥有了判断文件内容经过两次 Bae64 之后是否有等号的 Oracle 了,但是这仅仅只是判断有等号,这种情况还包括了 1 或者 2 个等号,况且,我们最终的目的还是需要获得拥有两个 = 的 Base64 编码,仅仅只是能判断有没有等号还是不行。
e.找到特殊的base64
我们再仔细回顾一下 Base64 的编码规则,等号是由于 Base64 编码填充形成的,对于等号填充形式,基本上我们有三种状态:1 个等号、2 个等号、没有等号。而其实这几种状态又是可以相互转移的,我们分别考虑:
- 在没有等号的情况下,字符串长度 n ,总 bit 长度为
8*n恰好为 Base64 分组 6的倍数,此时如果我们再添加2+3*k (k>=0)个字节即可获得 1 个等号的填充;或者再添加1+3*k (k>=0)个字节即可获得 2 个等号的填充 - 在有 1 个等号的情况下,字符串长度 n ,总 bit 长度为
8*n = 6*(n+2) - 8 = 6*n +4,此时如果我们再添加2+3*k (k>=0)个字节即可获得 2 个等号的填充;或者再添加1+3*k (k>=0)个字节得到没有等号填充的状态 - 在有 2 个等号的情况下,我们不需要额外填充
在我们上述的oracle攻击中,无法判断原来的内容编码后有多少个等号,但是我们可以通过判断出没有等号的情况,那么我们是不是可以通过没有等号的情况,将其转移成固定有两个等号的情况呢?
所以我们接下来我们需要找到一个可以产生 1+3*k 或者 2+3*k 字节的编码形式。
这样的话选择就有很多了,例如
convert.iconv..CSISO2022KR 编码,可以在头部添加固定字符\x1b$)C
这时就又回到我们状态转移的问题上来了,虽然我们无法判断有几个等号,但是我们可以判断没有等号的情况,而我们知道通过之前的 Oracle ,只有没有等号的情况是无法产生报错的,而这几种状态是可以相互转移的。
所以!我们只要覆盖这三种状态,判断出哪一种是没有等号的状态,再对其进行状态转移即可:
- 首先通过对原内容进行编码的为状态 1 :convert.base64-encode|convert.base64-encode
- 通过增加了 1 次 4 字节冗余编码的为状态 2 :convert.base64-encode|convert.iconv..CSISO2022KR|convert.base64-encode
- 通过增加了 2 次 4 字节冗余编码的为状态 3 :convert.base64-encode|convert.iconv..CSISO2022KR|convert.iconv..CSISO2022KR|convert.base64-encode
因为根据上文对 Base64 编码规则的推断,每增加一次 4 字节冗余就能使得编码状态发生相应的转移,所以无论最初的状态 1 是什么,以上三种都能覆盖等号的三种状态。
然后我们再用之前提到的 Oracle 判断其中没有等号的状态,再将其转移到有 2 个等号的状态,就必定能产生满足我们有 2 个等号的 Base64 编码了!
原作者脚本:
1 | print('detecting equals') |
4.处理剩余字节
根据前三步,回顾一下我们解决了哪些问题
- 必定产生一个带有 2 个等号的 Base64 字符串
- 可以让字符串中任一字节移动到首位
- 可以利用 dechunk 判断字符串首位是否在 a-fA-F0-9 范围内
虽然完成了这三部分,但是我们现在只能判断字符是否在一个大概范围内,我们接下来的目的就是设法准确判断第一个字节.
根据前文的思路,那么我们会想:是否存在这么一些 filter ,可以单独对每个字母生效将其转换到 a-fA-F0-9 的范围内呢?
比如假设有这么一个 1to1 的 filter ,它只对 z 字母有效,可以把 z 转换到 a 字符,对其他字母都不生效;这样一来,如果第一个字母是 z 的话,我们就可以利用这个 filter 将其转换到 a ,再利用最初的 Orcale 进行判断了,此时就不会产生内存错误;而如果不是 z 的话,就不会被转换,仍然产生内存错误。
不过要找到的话很难,我们可以退而求其次,先判断出一些字母,这些字母集合为 A ,其他另外某几个字母集合 B ,倘若有这么一个 filter 可以判断 A ∪ B ,但是因为集合 A 已经被我们排除了,所以这个 filter 尽管没有很满足我们 1to1 的要求,但是也能协助我们转换 B 集合部分的字母。
1 | rot1 = 'convert.iconv.437.CP930' |
利用string.tolower我们可以把所有大写字母转换成小写字母,这样我们只用分析小写字母和数字了
a-f
由于a-f,0-9这个范围,我们可以直接通过dechunk来判断出范围.
接着通过一次rot1转换,,我们可以把f排除范围了,
1 | var_dump(file_get_contents("php://filter/convert.iconv.437.CP930|dechunk/resource=data:,a")); |
接着判断a-e,由于rot1对a-e都生效,所以多次应用rot1即可逐个排除
但是我们怎么判断排除a-e之后剩下的是f呢?万一是数字呢?所以我们还需要找到一个对 f 生效,对数字不生效的 filter ,于是作者得到的 filter 如下:
1 | var_dump(file_get_contents("php://filter/convert.iconv.CP1390.CSIBM932|dechunk/resource=data:,f")); |
这样我们就能判断字符f了.
此处作者脚本:
1 | # a-e |
使用了 be 编码,作者实际是较长的字符串进行判断的,在处理较长字符串的时候可能存在不可见字符等冗余问题需要去除
n-s i-k v-x
借助rot13,可以将n-s转换成a-f
对于i-k在rot1编码规则中会将i->q,再次使用rot13可以得到d-f
1 | var_dump(file_get_contents("php://filter/convert.iconv.437.CP930/resource=data:,i")); |
借用rot13,可以将v-x转换成i-k的范围,然后复用上述步骤
此时我们解决了2*6+3*2=18个字母,还剩8个字母与数字来判断
检索数字
在 Base64 编码中,因为编码规则都是相对固定的,尤其是相对字符串第一个字节来说,因为在 Base64 分组的时候,第一个字节可以直接编码得到 Base64 编码中的第一位,以 1 为例,如下:

根据前面的我们现在可以判断所有字母了,也可以分清字母和数字了.
所以倘若我们把所有数字提取到第一位,并进行一次base64编码,得到的编码结果我们再去判断第一位是什么字母,就可以大概推出数字的范围:
1 | 0-3 -> M |
然后我们再使用 r2 交换 Base64 的第二位,因为在 Base64 分组中,Base64 的第二位的高 bit 位仍然受到原文第一个字节的影响,所以根据编码结果第二位的范围我们就可以最终确定这个数字是什么了!例如 0-3 :
1 | 0 -> CDEFGH |
当然仍然有可能编码结果下一位仍然是数字,例如 3s 编码结果为 M3M= ,但是根据我们之前把 0-2 都排除了,剩余的就剩下是 3 了,所以依旧可以判断出来。
其余数字类似,就不再赘述。
至此,我们就完成了所有字符的翻译工作了,这个oracle文件读取攻击的原理也被阐述完全了